Reasonable Code Organization
The following are some excerpts related to code organization from a code review I did recently.
I started reviewing this PR and wasn't quite sure exactly what the separation of concerns were with the boundaries you had drawn. So I drew a diagram to try and help myself understand better. It ended up looking as follows.
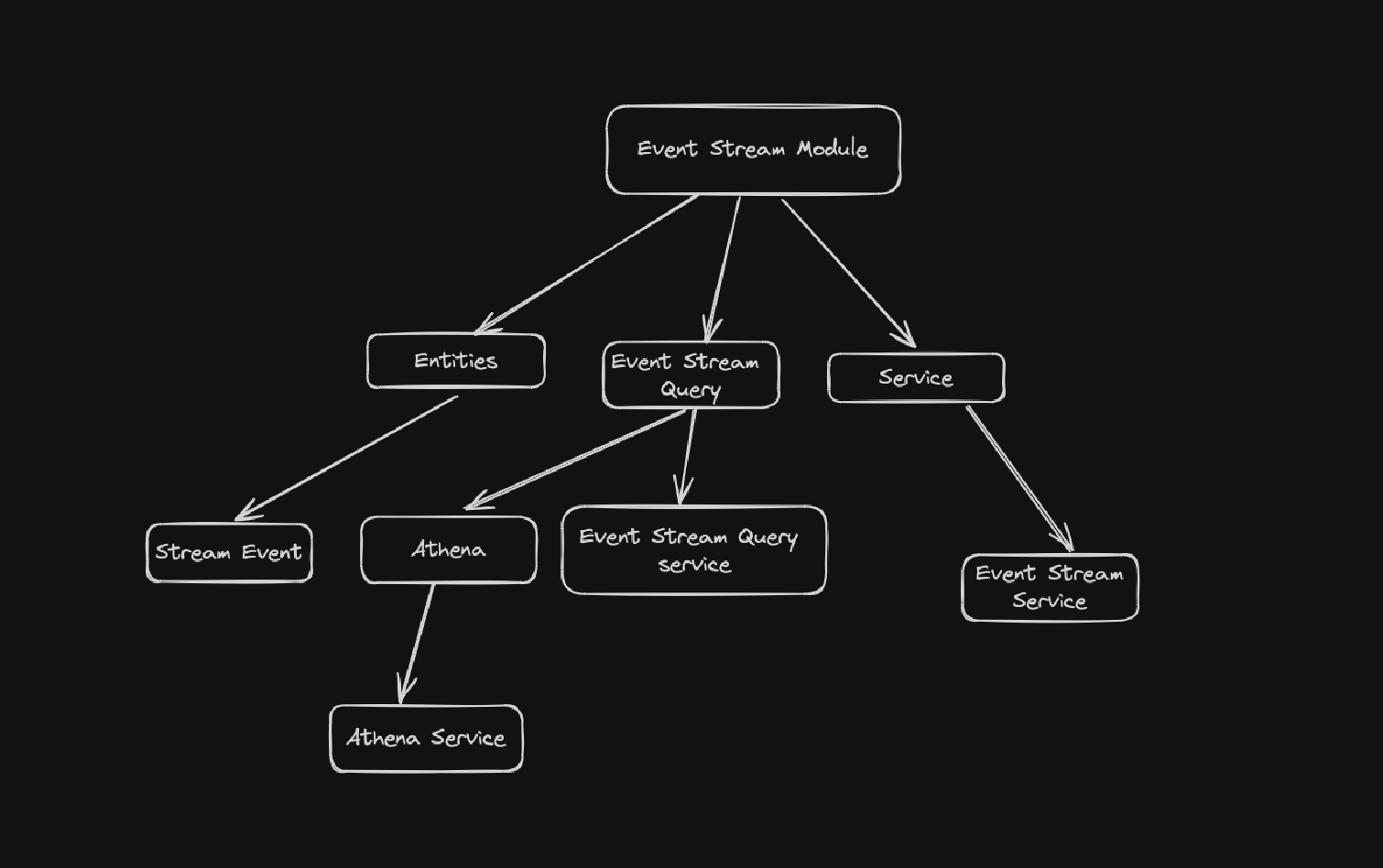
From looking at the code in far more depth I started to get a better understanding but still wasn't sure about things. Largely, what component was responsible exactly for what concerns.
I figured out through reading a bunch of the code that
EventStreamQueryService was for querying Athena for Events. Which roughly
lines up with the diagram above. Part of what threw me on that was the naming
having Stream in there. The following questions were flowing through my head.
- what does
Streamhave to do with querying? - is it integrated with a stream somehow?
- why is Athena a peer?
- is something else using it?
Beyond that even when I looked at the code of the Athena service it
has knowledge of Events which isn't an Athena thing at all.
So, I figured I would throw a quick diagram together to show how I would think about this problem architecturally and how I would draw the lines. That looks as follows.
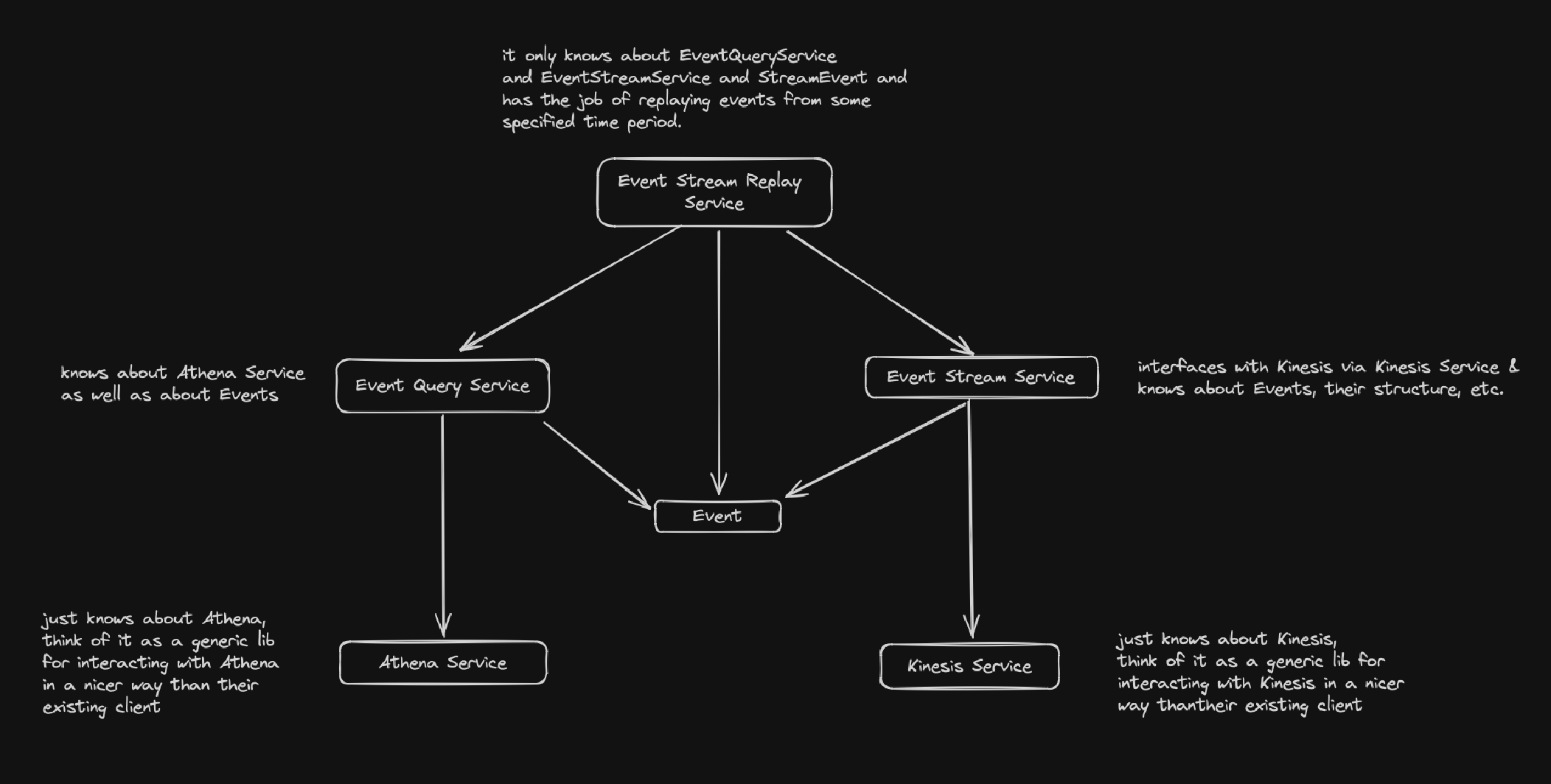
I tried to explain the responsibilities of each of the concepts in the text next to it. The arrows represent their relationship in terms of dependence (what things depend on what things). This generally helps in terms of making decisions about encapsulation of dependencies (a.k.a. are you going to hide a dependency away or are you going to expose it intentionally for other things to use it).
This naturally leads to the question. "How do you organize this code so that it is far more consumable and easy to understand coming into the project?"
That is where modules come into play as they facilitate encapsulation of dependencies as well help to formalize interfaces. It is worth noting that I am not talking about Nest.JS modules, though they can also facilitate encapsulation. I am simply talking about standard Typescript modules. If we take the example above you could create a directory structure as such.
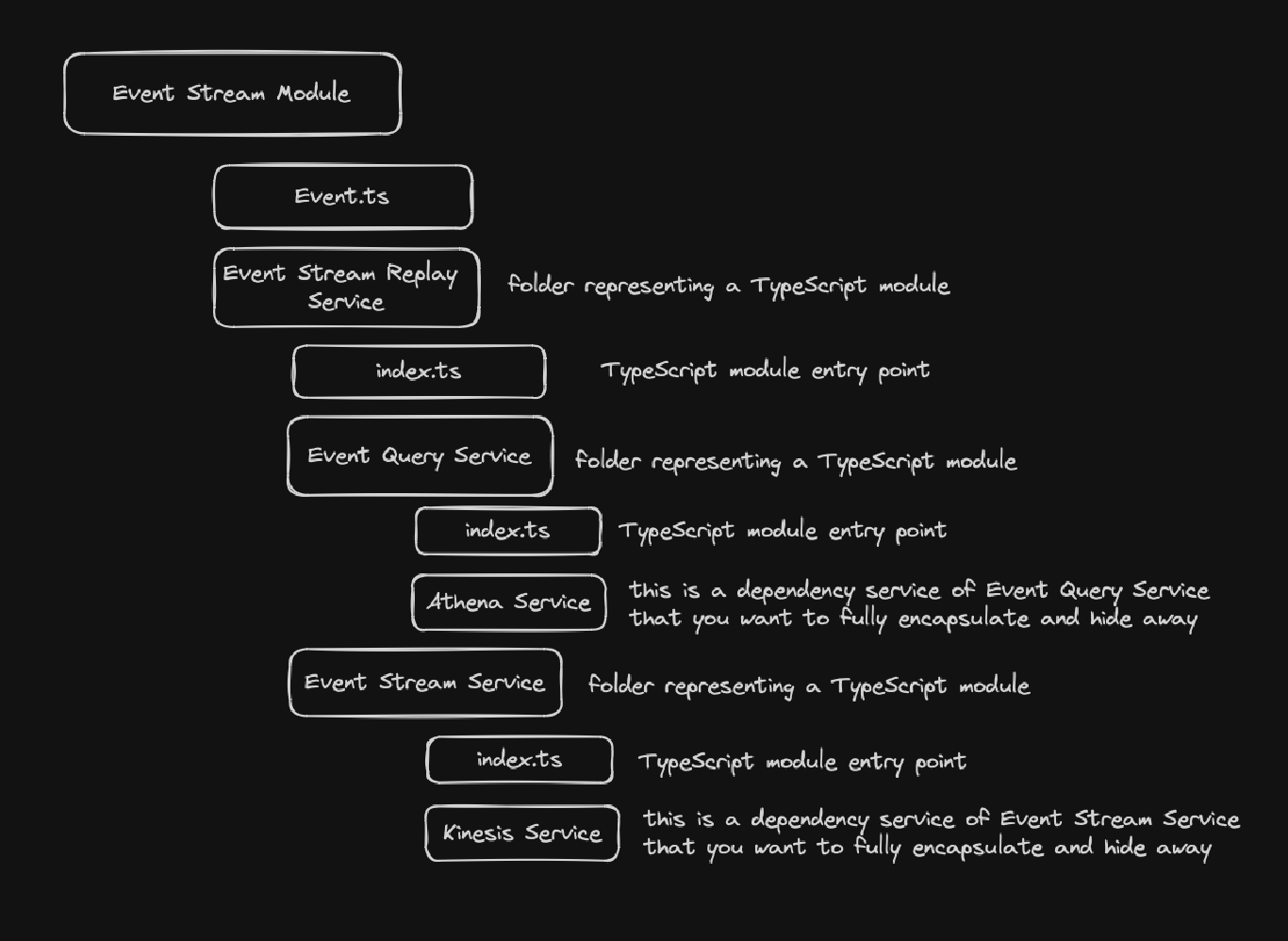
Having a directory structure like this is extremely valuable because of the
encapsulation. It tells me that as a consumer and developer of the Event Stream Module, that the Event and EventStreamReplayService are the public interface and
entry point for the module. I know this very quickly just from looking at the
directory structure. Everything else is encapsulated and hidden away with in
their respective modules. This is also extremely useful to know as a developer
because I can understand for example that EventStreamService depends on
KinesisService but that nothing else should because it is encapsulated within
the EventStreamService module.
The same goes for EventQueryService module. It encapsulates the Athena Service telling me as a developer nothing else should be using that Athena Service. Instead, they should be going through the EventQueryService or if
some functionality doesn't make sense being added to EventQueryService then
the AthenaService should be elevated up to a higher level shared dependency.
All of this, aids massively in communicating the boundaries and their actual association to the architecture itself.
Something like what we originally had doesn't tell us much.
It tells me that a StreamEvent exists that a EventStreamQueryService
exists, that a EventStreamService exists, and that a AthenaService exists,
but it doesn't tell me much of anything about their relationships or what their
responsibilities are intended to be.
Not having clear boundaries allows you to easily fall into traps that make your
code far less maintainable and reusable. For example if we look at the
AthenaService.fetchQuery() method.
async fetchQuery(
queryExecutionId: string,
nextToken?: string,
): Promise<Result<EventStreamQuery, AthenaServiceError>> {
try {
const data = await this.client.send(
new GetQueryResultsCommand({
QueryExecutionId: queryExecutionId,
NextToken: nextToken,
}),
)
const events: EventStreamEvent[] = []
data.ResultSet?.Rows?.forEach((row) => {
events.push({
eventSource: row.Data[0].VarCharValue,
projectId: row.Data[1].VarCharValue,
occurredAt: new Date(row.Data[2].VarCharValue),
payload: JSON.parse(row.Data[3].VarCharValue),
})
})
return Ok({
queryExecutionId: queryExecutionId,
state: EventStreamQueryState.SUCCEEDED,
nextToken: data.NextToken,
events: events,
})
} catch (error) {
return Err(this.mapError(error))
}
}It is building a EventStreamQuery object as well as building an array of
EventStreamEvents. This is a mixing of two concerns here. One is the work
necessary to deal with Athena client and the other is work that is structuring
data to be Event data.
Let's say we decided to use Athena for something else in the future in this
project, or who knows maybe in another project. Because these two concerns are
mixed here it would require much more work to rebuild all the context around
this problem space and safely do the extraction of just the Athena specific
piece that could be reused. Keeping those boundaries clean now doesn't
cost very much at all as the context is already present.
If you aren't clear on TypeScript
Modules it is a
standard language feature that is worth understanding. The pattern of having a
directory represent your module with a index.ts file in it can be very
useful.
To complete the exercise with the same type of diagram I started with, but in this proposed new world order. It would look like this.
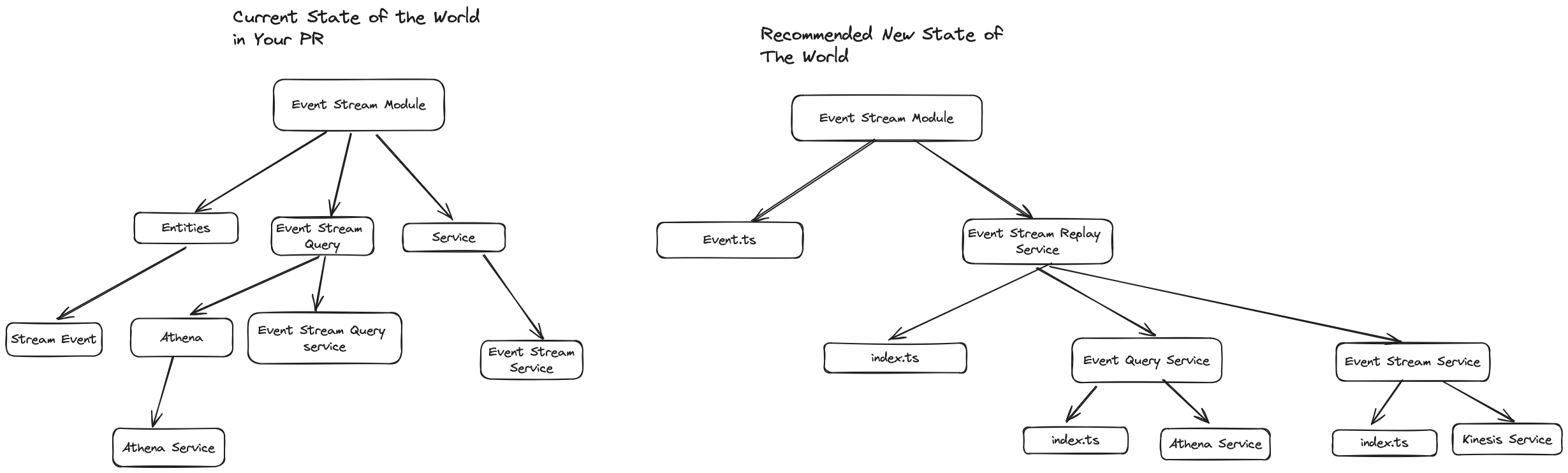
This is of course possible to do with Nest.JS modules. However, it doesn't really give you any advantage and adds more boilerplate code and complexity than is necessary.
I hope this has been useful and am always open to discuss further.