Git Commit Creation
When people are first learning Git they seem to learn something along the lines of the following.
You can create a commit by doing the following.
- staging a change with
git add <path/to/file>- create the commit with
git commit
Or maybe something like.
You can stage and commit in one shot with
git commit -a.
It seems that for the majority of people, once they learn the above about creating commits, they just move on and never look back. In my opinion this moving on and never looking back has massively delayed individual growth as well as hindered the development of maintainable systems.
So with this article I am attempting to provide the ultimate guide to Git commit creation. In the hopes that it will help newer developers understand everything that they should be taking into consideration when creating a commit. And who knows, maybe we will be lucky and a couple of those devs that haven't looked back, will slow down for a minute and think about creating Git commits again.
The Pressures
To really start to understand how we should be creating commits, and the reasons why. We need to explore the pressures imparted on Git commit creation from Git itself, the needs of our team members, both right now and in the future, as well as the needs of our selves, both right now and in the future.
Anatomy of a Commit
To start we really need to understand what commits are in Git. Technically from a Git perspective a commit is a snapshot of a project's contents, files & folders, at a moment in time combined with a message.
Snapshots & Diffs
In the Git repository these snapshots are related to one another through the concept of ancestry. Meaning that generally each commit has one or more parent commits. These parent commits are the ancestors of the commit.
Side Note: There is technically a special case of commit that doesn't have any parents. Commonly you will see this with the first commit in a repository. However, you can actually create multiple of these within a repository if you like. If you are curious this is generally referred to as an "orphan" branch and can be done with
git checkout --orphan. See the git-checkout man page for more details if you are interested.
So we have snapshots with messages, and they have ancestors. What is the big deal?
Well, the natural thing that falls out of a snapshot having an ancestor is that
there is a difference (a.k.a. diff) that exists between two snapshots. In fact
this is such a prominent mental model that when you do a git show <sha> it
shows you the difference between the ancestor commit's snapshot and the
snapshot of the commit identified by the given <sha>.
A lot of people choose to simply think about commits as diffs even though they are actually storing full snapshots of the project in the Git repository.
Commit Message
The message portion of the commit is an extremely important and valuable piece of information, that if used properly, facilitates code reviews, as well as short-term and long-term maintenance and understanding of a code base.
Git actually has an official format for Git commit messages, which is as follows.
Short summary of change (<= 50 chars in len)
One or more paragraphs of text.
(hard wrapped at 72 characters)If you are working with any editor worth its salt. It will have support specifically for the Git commit message format and help you abide by the constraints of this format.
Abiding by this format is important as it will make sure that our commit messages work within Git as a tool and it's expectations.
Commit Characteristics
In addition to understanding the anatomy of a commit, their associated requirements and implications, it is also important to understand the expected characteristics of a commit within Git.
When you are making a commit. Two characteristics that are important to make sure you take into consideration are that the commit is buildable and testable.
Buildable simply means that the snapshot that will be captured by the commit, is able to build without failure, using the build system of the project. This is applicable not only to compiled languages but also can be conceptually extended to include other tooling like linting and formatting.
Testable simply means that the snapshot that will be captured by the commit, is able to successfully run the automated tests without failure.
These are crucial for a number of reasons. For one, Git provides tools that
depend on these characteristics being met. For example git bisect, an
extremely valuable tool that aids in automating finding a commit that
introduced a particular issue. If your commits aren't buildable and
testable git bisect doesn't work in an automated fashion.
When your commits are not testable your team will quickly lose faith in the value that the test suite is providing, which will generally result in people's testing practices waning, likely due to the Broken Windows Theory.
Beyond that if your commits are not buildable your teammates will quickly become irritated with you because your commits will be impeding them from making progress on the things they are trying to push forward.
Scope & Intent
At this point we know that that commits have a snapshot of the project and an associated message that should abide by the official format, and that the commit should be Buildable and Testable. However, we don't have any real guidance in terms of what should be included in the snapshot and the commit message.
This is where scope and intent come into play. Scope and intent are the key to one of the most important software engineering practices of today, understanding and properly defining commits.
When we are making changes to software it is crucial to think about the intent behind the change. This can also be thought of as simply answering the question, "Why was this change made?" However, thinking about the intent alone is not enough. We also need to think about the scope in terms of the various irreducible (a.k.a. atomic) components of the proposed change. This is due to the fact that the intents of a change are the combination of the individual intent of each irreducible component.
This sounds a bit theoretical at this point. But it is actually something that is quite concrete and is very easy to see when simply looking at a pull request's changes. All we have to do is ask ourselves the question, "Why was this change made?", and then as we are looking at the code, validate whether that specific code change aligns with that intent.
I recently reviewed a pull request that was created to tackle a particular bug. However, when looking at the pull request there were a lot more changes than I expected to see. I wasn't sure why those changes were there, but they didn't seem to be required to fix the bug.
At this point there is no way anyone should sign off on this pull request as we really have no idea what it is doing, let alone, why these changes were made.
So I talked to the developer that made the pull request and through conversation we determined that the changes that weren't specifically fixing the bug were made for a handful of different reasons, to eliminate duplication, to fix linting errors/warnings, and to clean up a toggle.
It looks like we have a bit of a miss alignment here in terms of intent because we have code that exists with intents other than fix the bug. More accurately, we have a bit of scope creep.
If we look at the pull request visually in terms of intents and scope it would currently look something like the following.
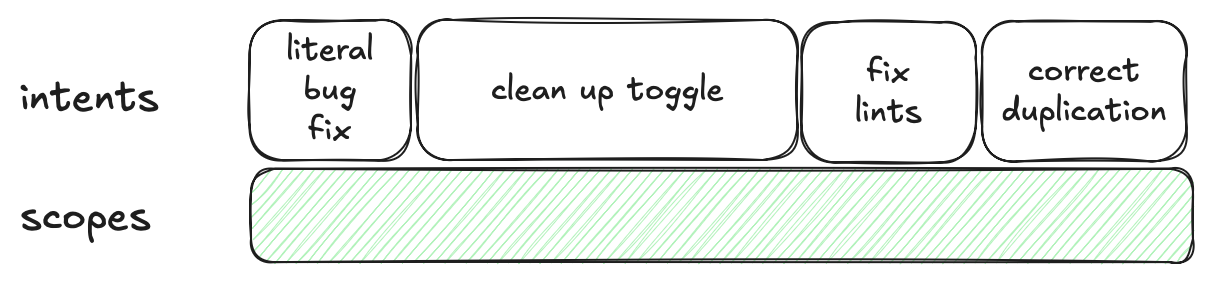
In the above we can visually see that in this case the current scope of the commit involves the following intents.
- Commit A
- literal bug fix
- clean up toggle
- fix lints
- correct duplication
But, it is a single commit and that commit only has one scope. You could theoretically argue that you can include in the commit message details describing that the commit addresses all these intents. But that would not address the issue that when looking at the code you wouldn't be able to distinguish if a line of code was changed to fix a linting rule or changed to address the duplication, etc.
So a much better approach is to create separate commits, one for each of the intents. This binding between an intent and a commit, which has a singular scope, is a crucial underpinning to building maintainable software systems efficiently.
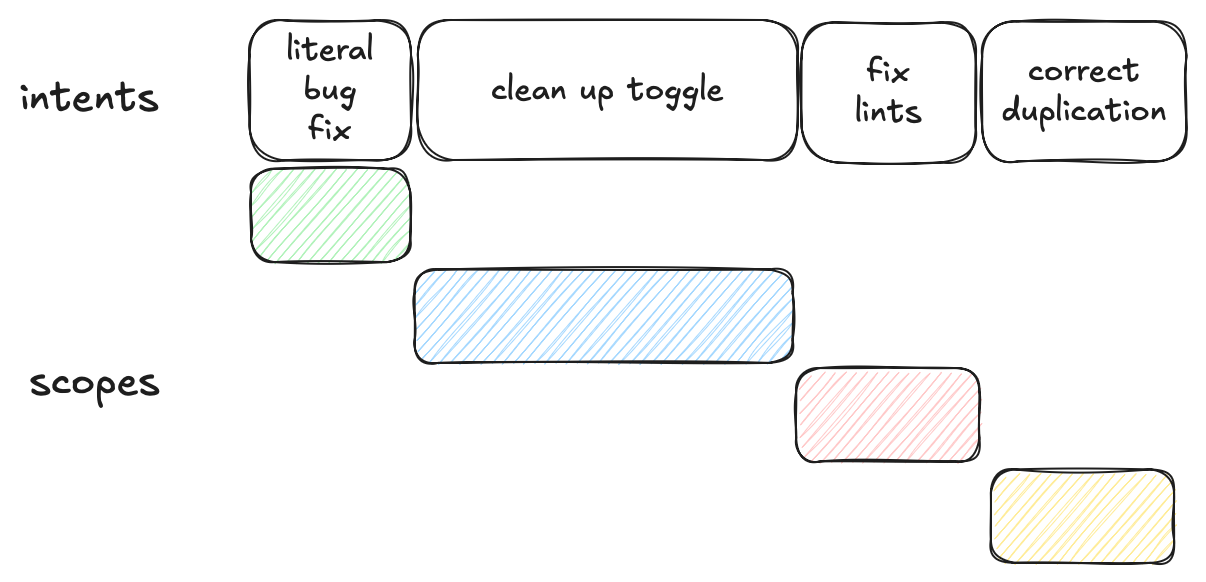
The above visually represents each scope as a different commit paired with each respective intent. So we would effectively have the following commits.
- Commit A: literal bug fix
- Commit B: clean up toggle
- Commit C: fix lints
- Commit D: correct duplication
This fundamentally makes the peer review process go much quicker as the commits are focused on a singular narrowed intent, and provide the critical context in the commit message.
Intent & Architecture
As the old adage says, "There's more than one way to skin a cat." That statement is true in the context of defining intents as well. However, that doesn't mean that all the ways of defining intents are equal.
For example. We could take and break out our commits for a project as follows.
- initial set up of listing action v2
- added api calls, and computed variables to allow for checking which CTA to display
- finished functionality for all of the child components
If we look at the summaries we can maybe draw the following diagram based on understanding.
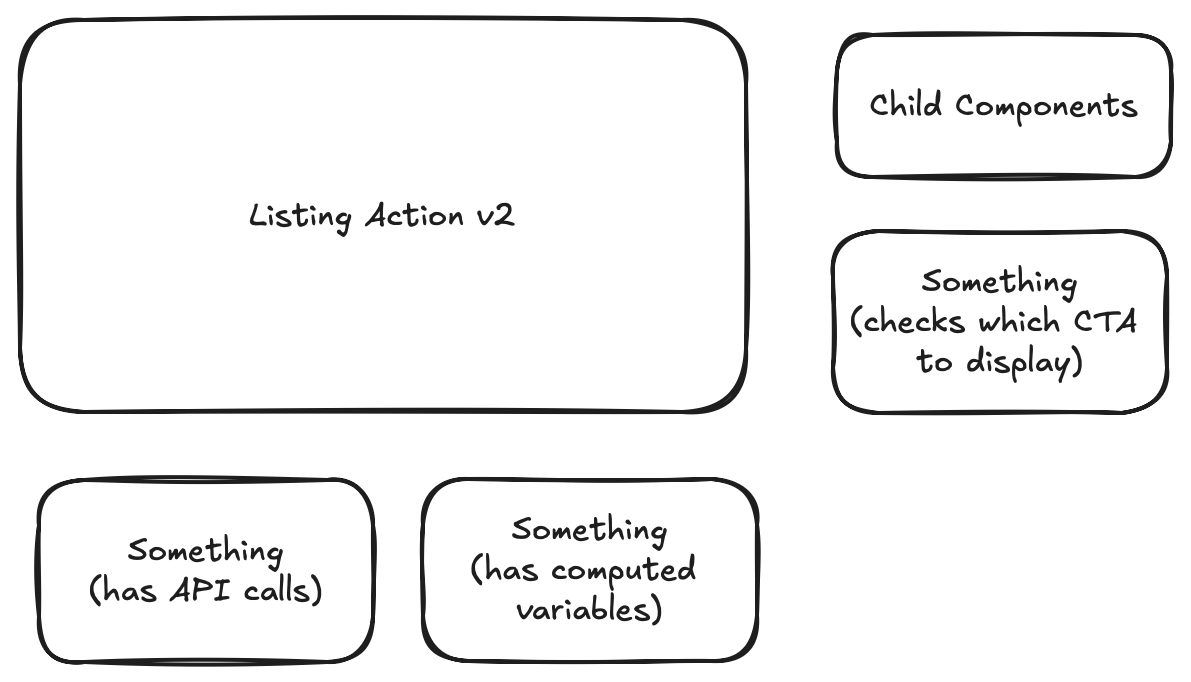
If we just look at the summaries and diagram above we can gather the following.
- That there is some initial setup. Though we are not sure what that is exactly without looking deeper.
- That some API calls and computed variables were added to facilitate checking which CTA to display. But we don't have any information about what component(s) are responsible for/involved in this.
- We know some sort of work has been done to finish the functionality for all the child components. But we don't know what that is without looking deeper.
- And we know that there is some concept of listing action v2 but don't really understand how it relates to anything else.
The above is technically broken out into intentions. The first intention was, "setup listing action v2", the second was "add api calls & computed variables to allow for checking which CTA to display", and the third was "finishing up some functionality".
It is worth noting that the second intention has a smell as it has the keyword, and, in the description. Hinting there are probably multiple intents within the scope of that commit.
Despite multiple intents in that scope, this is definitely a step in the right direction as the commits are broken out into intentions.
But we can do much better with a slight shift in our thinking about intents.
If we add the constraint that our intents should generally be related to application architecture concepts. Things like modules, classes, methods, functions, services, etc. We would have likely defined the intents and commits as follows.
- add can apply, reason props
ProfessionalViewListing - mod
ProfessionalListingAPI client to map props - add listing actions components (e.g.
AcceptShift) - add
ListingActionV2to show proper action component - register the
listing_action_v2_fetoggle - mod the
Listingview to showActionV2orActionV1
This is fantastic as now we have lots of information just from the summaries of these commits. In fact, it gives us enough information to draw the following diagram of the architecture involved.
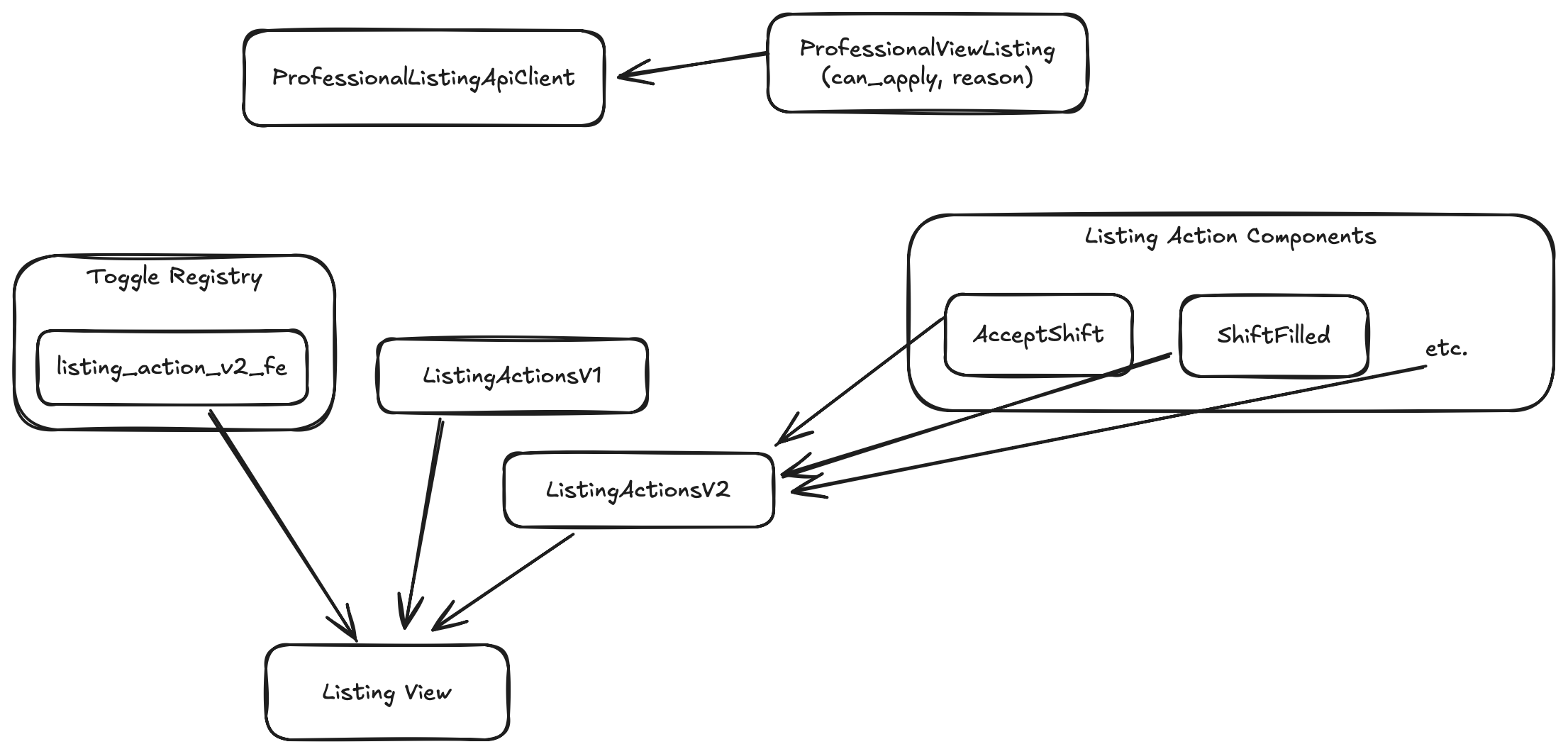
So from the above diagram we can see that the commit summaries containing intent around different architectural concepts, as an approach, has provided us with a lot more value in terms of understanding changes as well as the code base itself.
In particular, we know that there is some sort of collection of Listing Action
components and that the ListingActionV2 component is responsible for choosing
which one to render based on some criteria. We also know that the Listing View exists and that it conditionally chooses to render either the
ListingActionV1 component or the ListingActionV2 component based on the
registered listing_action_v2_fe toggle most likely. We also know that there
is a ProfessionalViewListing that received the can_apply and reason
properties. As well as that there was a ProfessionalListingApiClient which
was modified to map properties, which are most likely the properties that were
just added in the previous commit.
We were almost able to build a complete architectural diagram expressing the relationships between the various components involved just from the commit summaries. The one thing we are missing is just how the API client relates to the rest of the architectural concepts.
It is amazing how valuable this is and how much it facilitates rapidly gaining context around an area of effort. So, I hope this makes it clear that even though we can define intents in a bunch of different ways. We generally should define them based on architectural concepts due to the massive gains that we get.
Fallback on Scope & Intent
Now, you may have noticed that I said aligning your intent is generally the right thing to do. That is because there are scenarios where it may not be fitting. An example, where you would likely want to fall back to simply using Scope & Intent to define your commit, is when you are switching from not having automated formatting in a project to having automated formatting.
In this case you could try and argue that you could format sections of the code based on architectural concepts. Though, generally this isn't practical due to the fact that the tooling doesn't make it easy to apply auto formatting only to an architectural concept within the code, and secondly because most of the time people don't have a solid well organized architecture to help with this.
So instead you create a commit that formats all the files in the code base. It could be thousands of files, but you get it done in one fell swoop. And you make the summary of the commit clearly communicate the scope & intent of formatting all the files.
A similar scenario would be enabling linting across a project that didn't have linting before.
In my experience scenarios that are incompatible with architectural alignment are pretty rare. So we should always make sure we are putting effort in to strive for architectural alignment and only fall back to solely scope and intent after exhausting all the ways to facilitate architectural alignment.
More than a summary
At this point we have great guidance in terms using scope & intent to define our commits and their commit summaries. And we have learned how valuable a commit's summary can be when the commit is defined with a singular intent around architectural components. However, the commit summaries are limited to 50 characters, or less. Which makes it difficult to fully communicate the intention of a change. Let alone provide any additional information about the approach that was taken and why.
Luckily, the Git commit message format supports providing any number of paragraphs of detail as long as they have blank lines separating them, and they are hard wrapped to 72 characters. This allows us to define our own Git commit format based on the official Git commit format plus our learnings from above.
The following is a Git commit message format I have refined over the past 24+ years of development experience.
Short summary of change (<= 50 chars in len)
One or more paragraphs explaining the INTENTION & REASON
for the change. (hard wrapped at 72 characters)
One or more paragraphs explaining the APPROACH taken to
attempt to achieve the above described INTENTION or a
portion of the INTENTION. (hard wrapped at 72 characters)
Associated Ticket IdentifiersThe short summary should describe the change. I like to think of this as the what of the commit. It is valuable to give a high level understanding of what change the commit represents.
The intention & reason paragraph on the other hand is by far the most valuable part of the commit message as it is something that is impossible to get from simply reading the code. I like to think of this as the why of the commit.
Following that is the paragraph covering the approach. This is something we can kind of get from reading the code, but not entirely. So we include this as additional context in the commit message. You can think of this as the how of the commit.
Lastly, we provide any associated ticket references. This facilitates ticketing systems tracking commits and their association to tickets in the ticketing systems. This is an extremely beneficial thing to include as it facilitates going back and finding even more context about a change.
So for every commit we provide the what, why, how, and associated tickets so that peers reviewing the changes have all the associated context and so that in the future if we, or another dev, need to understand the intent and context of a change we can easily get it from the commit message.
Proof of Work
When you create your commits taking the above into consideration another natural benefit appears. It is something that prominent development teams, like the Linux Kernel and Git development teams, talk about in respect to their Git commit requirements. It is this concept of Proof of Work.
The idea is that when you submit a series of commits in a particular order, the commits and the order should communicate the steps you are taking to accomplish the higher level goal & intent of the pull request or patch series.
Think of the commits being the equivalent of writing out the steps you performed when solving a math problem as a kid. In fact, it carries the same benefits. It helps you and others see how you got to the resulting answer. And if that answer isn't 100% correct, it helps you or others see the various steps you took and be able to investigate or validate each one of them.
Additionally, if we are following the practice above of binding scope and intent to architecture, then it also provides an understanding of how the greater intent was accomplished in the terms of the application architecture. This is extremely valuable from both a peer review standpoint, and from the standpoint of trying to understand changes at a later point in time.
Tactics
We have covered some of the details about what commits are, what their contents and message should contain, and the arguments backing them. However, we haven't really started covering how you actually go about creating commits like this. So let's shift more into the mental hurdles and the tactical skills needed to actually create better commits.
Commit Permanence
One of the biggest hurdles people seem to have when shifting from making horrible commits to making great commits, is breaking this misconception that commits are permanent the moment you create them.
I don't know where this misconception comes from. But in my experience it is quite prevalent. But it is clear that it doesn't come from Git proper. You can see this fairly quickly just by looking at some of the operations that Git facilitates you performing on commits.
git commit --amendgit commit --fixup rewordgit commit --fixup amendgit commit --squashgit commit --reset-authorgit commit --author
The above is all just in the git commit command. There is even more once we
look into git rebase and other commands.
From looking at the above set of commands alone, it is clear from a Git perspective, that commits are made to be modified & mutated at least up until some point in time. It is also clear that, that point in time is not at the moment of creation of the commit.
So what is that moment of time when a commit should become permanent?
I would argue that it is the moment that a commit is integrated into the mainline branch. Prior to that moment the commits should be free to be refined and reworked.
Isn't Rewriting History Bad
If we take that stance though then we have to be ok rewriting history, even once it has been shared. And isn't rewriting shared history a big no no?
Yes and no. Let me explain.
There are cases where it is giant pain in the butt and can be extremely disruptive to other developers if you rewrite shared history. One such scenario is if you were to rewrite the history in the published mainline of a repository. In general, it is bad form to rewrite the history of mainline of a repository. Although, sometimes it is necessary and worth the disruption, e.g. to strip accidentally shared credentials, etc.
So just like everything else in engineering. There are pros and cons. We just need to make sure we understand the pros and cons and choose the path that fits our needs the best.
Rewrite Pull Request History
If we look at the scenario of rewriting history in a shared pull-request branch.
It enables us to have commits that can communicate a ton of context and value in terms of architecture. Additionally, it facilitates reverting specific targeted changes if necessary. As well as answering questions about the intent of changes over time in relation to architectural concepts. And bisecting to identify a specific change that introduced an issue and what the intention of that change was. Just to name a few.
At the same time it has the drawback that it can break direct code collaboration if there isn't communication between the parties. Generally though, there isn't much direct code collaboration on pull requests as the author is usually the one making the changes. And if the reviewer wants to make a change and push it up to the pull request branch. All they really need to do is let the pull request author know that they have pushed up a change, so they can manage integrating it into the final commit.
Squash & Merge
Another approach is to take a hard-lined stance about not rewriting any shared history, including pull requests. This means that the only way we can bring in changes from mainline is to back merge mainline into our branch. It also means that we can't refine our commits once they are pushed up to a pull request. In turn requiring us to add additional commits to the pull request that are not logically structured and are not representative of the application architecture or the intents at all.
This in turn results in a bunch of commits, that are meaningless to the Git
history existing within the pull request branch. And given that these commits
are generally not buildable & not testable they result in breaking git bisect and other functionality.
To help mitigate this people will do a "Squash & Merge" in which all the commits within the pull request branch are squashed together into a singular commit. This helps resolve the buildable & testable characteristics in the majority of cases. However, we have completely lost the ability to revert targeted changes and the ability to even understand the intention of the changes from an architectural perspective.
The only thing we have gained from this is "smoother direct code collaboration". Meaning that in the more rare scenarios when you are reviewing a pull request, and you want to push a change up to it. You don't need to let the author know that you are pushing a change up to their branch. Although you generally do anyway.
The Choice
The choice is pretty clear to me as the overhead of pinging the author via messaging is trivial, as a cost for rewriting pull-request history. And it unlocks a wealth of benefits. Enabling our commit's moment of permanence to be when the commit is integrated into the upstream mainline.
If you want to get a deeper understanding of this in relation to the Git tree. Check out my article, When to rewrite Git history.
But How do we do this?
You might be thinking. How do I actually accomplish this?
Learn Git
Well the extremely short answer is simply, learn more about Git.
It really boils down to learning a few commands, git add -p, git commit --amend, and git rebase -i. It is worth noting that it is crucial that you
have a solid understanding of Git commits and the Git commit tree in general
when truly understanding these commands.
The following is an outline of the related operations you would perform with each of those commands and links to respective documentation or guides.
Note: I included links to guides for Git Patch Stack, a
Git extension that facilitates a patch stack workflow with Git, because it
documents the main commit mutation operations with gps rebase which is really
just a convenience mechanism for git rebase -i.
- creating multiple commits from uncommitted changes
- Add hunks instead of entire file
git add -p <patch/to/file> - Use a Git GUI to stage individual lines or selections
- My article on git add -p won't split
- Add hunks instead of entire file
- amending a commit
git commit --amend git rebase -iProGit Book - 3.6 Branching - Rebasing git rebase -i manpage- edit a commit Git Patch Stack: Docs - Edit a patch
- reword a commit message
git rebase -iand mark forreword
- reorder commits Git Patch Stack: Docs - Reorder patches
- drop a commit Git Patch Stack: Docs - Drop a patch
- add a commit in the middle Git Patch Stack: Docs - Add a patch in the middle
- fix a commit up into another commit Git Patch Stack: Docs - Combine multiple patches
- squash commits together Git Patch Stack: Docs - Combine multiple patches
- split a commit up into multiple commits
WIP Commits
In addition to learning Git. There is another concept that is extremely valuable now that you are living in this world of commits that you evolve over time. And that is the WIP (Work in Progress) commit.
This is simply a convention of prefixing the commit summary with WIP: to let
ourselves know that the commit still needs further refinement before we submit
it in a pull request or integrate it into mainline.
Once we have refined it to the point that we are happy we simply update the
commit summary, removing the WIP: prefix. In turn finalizing our commit
conceptually.
Commit Message Template
Beyond that. There are things that are just hard to remember. The
various parts of the commit message can be one of those things. Luckily Git
helps us out by providing support for commit message templates via the
commit.template configuration setting.
If you want to set this up you can do so by running the following command.
git config --global commit.template ~/.gitmessage.txtThe above configures Git to look for the commit message at ~/.gitmessage.txt.
This template file is simply a text file that is loaded up into the editor when
you go to create a commit.
The contents of my ~/.gitmessage.txt are as follows.
# Short summary of change (the what) ( <= 50 chars )
# INTENTION of the change & REASON for change
# (Hard wrapped at 72 chars)
# APPROACH taken & WHY in relation to attempting to achieve INTENTION
# (Hard wrapped at 72 characters)
# Associated Ticket IdentifersThe layout I provided is based on making it efficient to enter. Starting out when it loads it in the editor it drops you into the top left corner ready to start writing your 50 character or less summary.
It is important to realize that any line in the Git commit message starting
with a # is considered a comment and will not be included in the final
commit message. This means that I don't actually need to replace any of these
comments. Instead, I just add the respective content below each comment.
The one exception to this is the short summary which is added above the comment
instead of below. It is also worth mentioning that you will want to keep a
blank line between each of these sections.
There are many more things you can include in your commit messages and the template to help you. Some people add explicit change log entries to their commit messages that are targeted at the consumers of the product rather than the developers. Others manage sign-off from peer developers through commit message standards they have defined, etc.
In my opinion, all these things can be valuable, and should be considered, but the above template really outlines the core that should always be present.
Buildable & Testable Enforcement
The buildable and testable characteristics are another thing that are easy to let slip by if we are just manually verifying them.
To help us hold to these requirements some people set up a Git pre-commit hook to make sure that each commit is buildable & testable prior to commit creation.
In my experience this isn't the ideal enforcement mechanism because it assumes that commits are final and that you aren't going to iterate on them or evolve them. Which we have seen above is pretty damn important.
A more appropriate hook would be a hook that is triggered when you want to either request that someone review a commit or integrate a commit. In turn helping make sure that any commit you are going to share either via integration into mainline or via pull request/patch is buildable and testable. Git doesn't natively have such a hook. But if you use Git Patch Stack it easily supports this via it's isolate_post_checkout hook.
You might be thinking. I don't need to worry about this. We have a CI (Continuous Integration) service that makes sure my pull requests are both buildable and testable. But in general this isn't a valid enforcement mechanism as most teams don't strictly only create pull requests consisting of a single commit.
So if we make sure that our commits are buildable and testable it in turn guarantees that our pull requests are buildable and testable. However, if we only make sure that our pull request is buildable and testable it is quite possible, if not likely, that one of the commits in the pull request in not buildable or testable.
Outside-In
Outside-In is an engineering practice in which you drive changes from the outermost thing first and work your way inward. Generally, the outermost thing is the UI layer.
The massive benefit of this is that you always end up building only what you need to build as it is driven by the need of the layer above. This is in opposition to inside-out or middle-out development in which you try and guess the needs of the outer layers and build the inner/middle layers first. Generally this results in your guesses being not quite right and having to do rework or even worse including additional complexity and functionality that isn't needed by the layers above.
Outside-In is extremely useful in helping you think about the architecture concepts. As you are effectively working from the outermost architectural concepts, to the innermost architectural concepts, and then working your way back up from the inside-out, connecting each of the layers.
Using WIP commits can aid this process as your outer layers can start as
WIP commits until you reach that innermost layer which ends up being a
complete logical chunk. Then as you work your way back up the layers connecting
them to the layer below you are effectively finalizing them and getting rid of
the WIP.
To get a better understanding of Outside-In with an example you can check out my article, How we should be using Git.
Conclusion
At this point you should hopefully have enough knowledge and context to be able to start creating meaningful, logically chunked, buildable and testable commits that are bound to scope, intent and architecture. Resulting in a valuable Git repository history that will aid you through the short-term and long-term maintenance and development of the project.